In this article we look into the sources and functions necessary to build a dimension’s hierarchy using an IBM Planning Analytics Turbo Integrator [TI] process. Read on to learn how to set it up, some best practices, and some troubleshooting tips.
What TI functions are used to create hierarchy in a dimension?
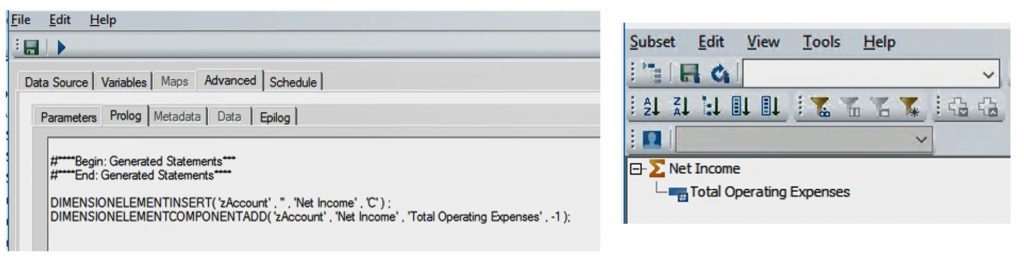
DIMENSIONELEMENTINSERT() and DIMENSIONELEMENTCOMPONENTADD() are the two main functions used to build hierarchy in a dimension. The insert function is used to add an element to the dimension and the component add function is used to nest a child element underneath a parent element.
Syntax: DIMENSIONELEMENTINSERT( <Dimension Name>, <Insertion Point> , <Element Name> , <Element Type> ) ;
Example: DIMENSIONELEMENTINSERT( ‘Account’ , ‘’ , ‘Net Income’ , ‘C’ ) ;
- All fields are expected as string inputs
- Insertion point is left blank using two single quotes to append new elements at the end of the dimension
- Element Type is either N/S/C for number, string, or consolidated parent
Syntax: DIMENSIONELEMENTCOMPONENTADD( <Dimension Name> , <Parent> , <Child> , <Weight> );
Example: DIMENSIONELEMENTCOMPONENTADD( ‘Account’ , ‘Net Income’ , ‘Total Operating Expenses’ , -1 );
- The weight field is expected as a number input with no quote marks
- If the parent element is a child, it will automatically be promoted to a parent
- WARNING: This will cause any data associated with that child element to be lost
Taking it to the Next Level
What can be used as a source to build a dimension’s hierarchy?
Building a dimension hierarchy using the hardcoding in the previous example would quickly prove tedious. The TI process to build the dimension hierarchy can use an ODBC connection, a flat file, or an existing Planning Analytics cube or dimension as its source.
The fastest way to have a dimension hierarchy built is from a delimited flat file containing a recursive parent child table. An ODBC connection can be used to connect to a similar parent child table coming from a database, such as a general ledger system. ODBC connections may be preferred if the dimension requires regular updates.
Setting up a recursive delimited flat file to build a dimension hierarchy
An excel file can be used to create and maintain a recursive table containing one record for each parent child relationship in the hierarchy. Columns for the parent, child, and weight are required. Extra columns for attributes or aliases, such as Description, can be added as needed.
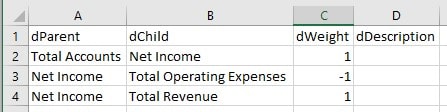
The Excel file is used for easy creation and maintenance. The Excel ‘Save As’ option can then be used to create a clean tab or comma delimited .txt or .csv file for the TI to read
Basic TI Process Setup
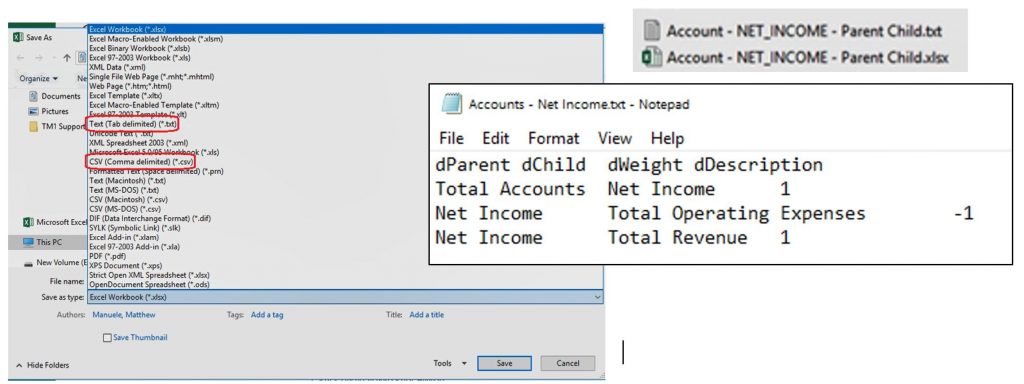
Data Source Tab
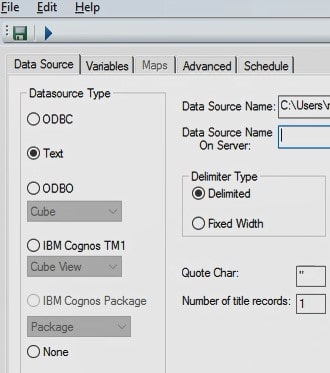
Once the flat parent child file is available, the Data Source tab on the TI process can be set up to read the flat file. Select text as the data source type and browse to the file. Set the delimiter and the number of title records and click preview to see the first 10 records of the file.
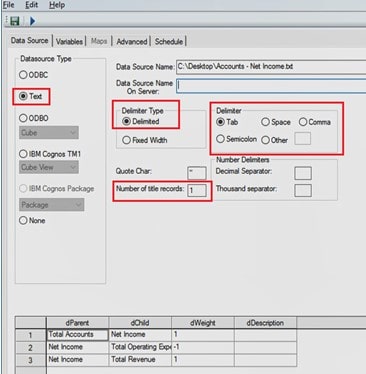
Variables Tab
Set the variables name, type, and contents on the variables tab. Choose Other as the contents. Note that we are specifically setting the variable type for the weight to be numeric.
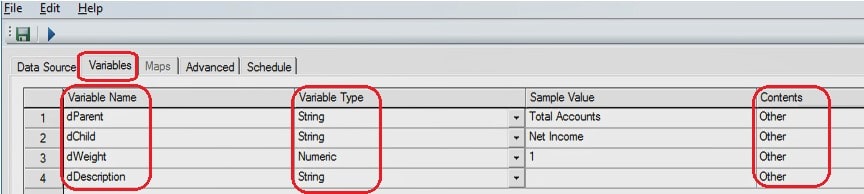
Metadata Tab
With the data source and variables set up, the metadata tab can now use the DIMENSIONELEMENTINSERT() and DIMENSIONELEMENTCOMPONENTADD() functions to the elements in the source file and build their hierarchy (dParent and dChild).
The Results
Running the process will now build the dimension using the parent child file as the source.
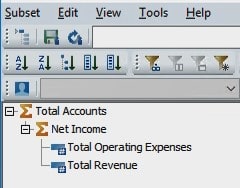
Why NOT to use the dimension editor
The manual dimension editor can display confusing layouts of the dimension that can lead to accidental element movement or deletion. This can be exceptionally dangerous because if a leaf level element is accidentally removed or promoted to a parent element, all of its associated data will be lost. If this were to happen by accident, that data could only be retrieved from a backup. The more complicated a dimension structure is, the better it is to use a source file and a process to build it.
Advanced TI Process Best Practices
This section assumes you are familiar with common TI Functions and standard processes and is for the more advanced developer.
The prolog, metadata, data, and epilog tabs can be used to perform a number of QueBIT recommended best practices.
Prolog Tab – Advanced
It is always best practice to use a boiler plate at the top of the prolog tab with any relevant notes about the process.
After the boiler plate, constants can be set for variables that will remain the same for the run of the process. The DIMENSIONEXISTS() and DIMENSIONCREATE() functions are used to ensure the dimension you are trying to build actually exists.
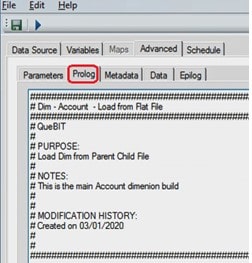
It is best practice to have Total, Alternate, Orphan, and Control Total as the only four ultimate parents. The DIMIX() function is used to check if the elements exist and the DIMENSIONELEMENTINSERT() is then used to create these ultimate parents. The main hierarchy of the dimension should live under the Total parent and alternate hierarchies should live under the Alternate parent. The Orphan and Control Total parents are for system maintenance purposes and are maintained by additional processes that are called and run from the Epilog tab.
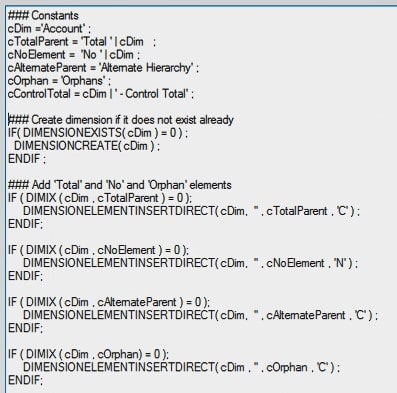
In addition, you should create another standard process to be called from the Prolog in order to flatten the hierarchy prior to rebuilding it. This allows existing elements to be moved around within the hierarchy without accidental duplication and unused elements to fall out of the hierarchy to be reviewed as orphans.
Once the hierarchy is flattened the DIMENSIONELEMENTCOMPONENTADD() function is used to ensure the catchall ‘No’ element resides under the ‘Total’ parent.
The ATTRINSERT() function is used create any attributes or aliases that will be coming in from the source, such as Description.

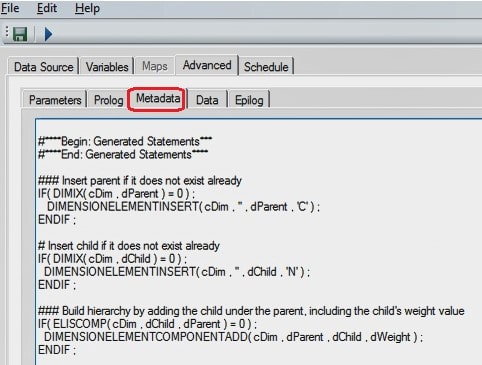
Metadata Tab – Advanced
The DIMENSIONELEMENTINSERT() and DIMENSIONELEMENTCOMPONENTADD() functions are used to insert the elements into the dimension and then create the hierarchy including any element weighting. The DIMIX() and ELISCOMP() functions can be used to check if an element already exists in a dimension or if the element already exists as a child of the parent.
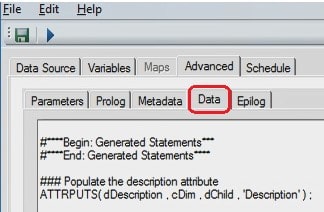
Data Tab – Advanced
The ATTRPUTS() function is used on the Data tab to assign string attribute data to the metadata dimension elements.
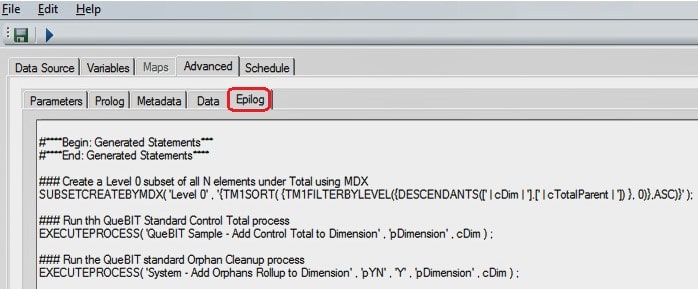
Epilog Tab – Advanced
The SUBSETCREATEBYMDX() function is used to automatically create useful dimension subsets such as one containing all leaf level elements in a dimension. The QueBIT standard Control Total and Orphan processes are called to perform their maintenance steps. The Control Total process populates the Control Total parent with every leaf level element in the dimension. The Control Total parent is useful when performing data validation, since it ensures a total value with no duplication. The Orphan cleanup process is used to find any elements that may have fallen out of the hierarchy and place them under the Orphan parent for review by the administrator.