
Geocaching with Planning Analytics

Geocaching is an activity in which you use a global positioning system (GPS) as a tool to seek “geocaches” (something(s) desirable or important to the “geocacher”) at specific locations all over the world. This process promotes learning about a specific environment (which you are most likely not familiar with) and sometimes helps sort it or clean it up.
As an example, in the United States, the state of Alaska is known for having a harsh environment with large, unsettled areas making it an excellent place to hunt for geocaches. But, what about a “technical environment” such as a Planning Analytics model that is new to you? Well, perhaps the “concept” of geocaching may apply there as well.
Often, as a consultant, you may find yourself in a situation where you have been given access to an existing model (using a TM1/Planning Analytics administrator role) but you do not have access to the machine its running on or any other type of environmental access — and you certainly will not be allowed to install any software or even take advantage of any OS utilities like Windows PowerShell, etc. and typically, restrictions exist preventing copying or downloading files.
So how do you efficiently search (do some geocaching?) through a model – say for all TurboIntegrator processes and Rules that reference a data item (a string, object, or other name)? For example, wouldn’t it be helpful to quickly generate a list of all processes (and rules) that reference a specific cube name? How about finding every process that executes a particular function? Establishing this kind of information is a critical part of a model assessment as well as when asked to establish a level of effort or estimate the impact (of a proposed change), identify objects (that require a specific modification or accommodation), or when creating data flow diagrams, performing debugging activities, etc.
Searching using a PAW Modeling Workbench
So, let’s start with what comes “out of the box”. With Planning Analytics Workspace (PAW), you can search at the “database level”, meaning any data item (cubes, dimensions, views, sets, processes, chores, rules, and control objects) in a model for a character string, using the search feature in the IBM Planning Analytics modeling workbench (introduced in IBM Planning Analytics 2.0.64). To use this search from within a workbench, you click the Search button (circled below), select the database (in which you want to search) and then enter the data item (or string) that you want to search for in the Search field and the results will appear in the panel below:
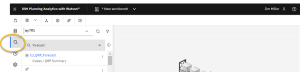
An added “bonus” of using this search is that you can click any search result to delete it from the database, open it in a tab to edit it, or depending on the type selected (i.e., TurboIntegrator process), run it or (Chore) enable it.
Note that to include control objects in a search you need to prefix the name with } and the search will then look for items that contain the string that follows the }.
The PAW Modeling workbench search works well, but it does have some limitations. For example, it requires executing 2 searches should you want to include control objects in your search. Additionally, the results presented are difficult to “capture” and make part of another document, and, of course, it isn’t available if you are not a planning analytics workspace user.
An “Organic” DIY Option
A simple and non-invasive (no special installs or setups, no additional executable required) alternative approach for searching through a model is to use Planning Analytics “itself” by employing 2 “simple” TurboIntegrator scripts which you can have an administrator add to the model or you can manually create them by following these steps:
- Create a new process and add 3 string (Type) parameters: pSearch (this will be the character string you want to search for), pObjectType (to indicate if you want to evaluate all processes or all cube rules) and pClearResults (which will indicate if the process should remove the search results “helper” object or not (more on this later).
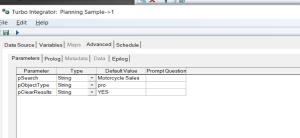
- In the Prolog section of the process, the below script can be added. Some explanation: this code establishes the process as a “master” which will “recursively call” (execute) a sub-process sending it specific parameters. The sub-process “scans” each TurboIntegrator process (PRO) file or cube rule (RUX) file looking for any occurrence of the pSearch value. Since the sub-process is executed repeatedly, it “adds” the search results to a results “helper” dimension. Finally, as a last step, the results helper dimension is read, and its values are written to a formatted HTML page. Here is the code:
# — some declarations
cProcessesDim = ‘}Processes’;
cCubesDim = ‘}Cubes’;
cResultsDim = ‘3’;
pDocumentName = ‘resultsme.HTML’;
DatasourceASCIIQuoteCharacter=”;
cProcessFile = ‘pro’;
cRuleFile = ‘rux’;
# — capture the total number of TurboIntegrator processes and Cubes in the model
vNumberOfProcesses = DIMSIZ(cProcessesDim);
vNumberOfCubes = DIMSIZ(cCubesDim);
# — capture this processes name
vProcess = GETPROCESSNAME();
# — create a helper dimension to accumulate the search results
IF (DimensionExists(cResultsDim)=0);
DimensionCreate(cResultsDim);
ENDIF;
vToLookFor = TRIM(pSearch);
IF (TRIM(pObjectType)@=cProcessFile);
vCounter = 1;
WHILE (vCounter<=vNumberOfProcesses);
sE = DIMNM(cProcessesDim, vCounter);
ExecuteProcess(‘2’, ‘p0’, Trim(sE), ‘p1’, vToLookFor, ‘p2’, TRIM(pObjectType) );
vCounter = vCounter + 1;
END;
ELSEIF (TRIM(pObjectType)@=cRuleFile);
vCounter = 1;
WHILE (vCounter<=vNumberOfCubes);
sE = DIMNM(cCubesDim, vCounter);
vFile = sE | ‘.’ | TRIM(pObjectType);
IF (FileExists(vFile)>0);
ExecuteProcess(‘2’, ‘p0’, Trim(sE), ‘p1’, vToLookFor, ‘p2’, TRIM(pObjectType) );
ENDIF;
vCounter = vCounter + 1;
END;
ENDIF;
‘ — set up some HTML for the output
ASCIIOUTPUT(Trim(pDocumentName),'<font size=”2″ face=”verdana”><h2><b><center> Search Results</center></h2></b></font>’);
ASCIIOUTPUT(Trim(pDocumentName),'<font size=”1″ face=”verdana”><b><center>The following objects contain reference(s) to your search: “‘ | vToLookFor | ‘” </center></b></font>’);
‘ — read the helper dimension and write the elements found to the HTML output
i = DIMSIZ(cResultsDim);
vCounter = 1;
WHILE (vCounter<=i);
sE = DIMNM(cResultsDim, vCounter);
IF (sE@<>vProcess);
ASCIIOUTPUT(pDocumentName, ‘<BR><center>’ | sE | ‘.’ | pObjectType | ‘</center>’);
ENDIF;
vCounter = vCounter + 1;
end;
‘ — clear the helper dimension
IF (TRIM(pClearResults@=’YES’);
DimensionDeleteAllElements(cResultsDim);
ENDIF;
- For the sub-process, you can create another new, TurboIntegrator process which will use a comma delimited text file as it’s Datasource. We want this process to have 7 Variables, so you can use Notepad to mockup a file as a starting point for the process – something like the following:

and then “connect” the sub process (to the mocked-up file) selecting Delimited and Comma, so that the process will “generate” 7 variables (V1 though V7):
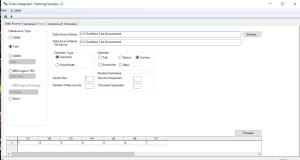
Next, (on the variables tab) , make sure that you set each variable’s “Variable Type” to String and its “Contents” to Other:
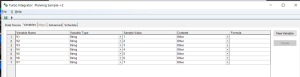
Add the previously mentioned 3 parameters (P0, P1 and P2) on the Parameters tab:
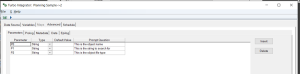
- Finally, to finish the sub process, you need to add some script to the Prolog and Metadata In the Prolog add the following 5 lines:
grabfile = TRIM(p0) | ‘.’ | TRIM(P2);
‘ — grabfile becomes the object name (TurboIntegrator process or cube name)
‘ — and extension (pro or rux)
Datasourcenameforclient=TRIM(grabfile);
Datasourcenameforserver=TRIM(grabfile);
‘ — tell the sub process what file to open as the Datasource
cResultsDim = ‘3’;
‘ — call the helper dimension “3”
sE = TRIM(P1);
‘ — P1 is the text string to search for
and in the Metadata tab, add these lines:
vConcatenation = TRIM(V1) | TRIM(V2) |TRIM(V3) |TRIM(V4) |TRIM(V5) |TRIM(V6) |TRIM(V7);
vScanResults = SCAN(sE, vConcatenation);
‘ — paste all the 7 variables into a single string variable and then use th SCAN function
‘ — to search it for any occurrence(s) of the text string we are looking for
IF (vScanResults>0);
DimensionElementInsertDirect(cResultsDim, ”, Trim(p0), ‘C’);
‘ — if there is any occurrence(s) of the text string we are looking for
‘ — then insert the name of the object into the helper dimension
ENDIF;
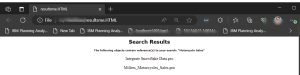
- When you run the master process, the search results are written to an HTML page for easy review:
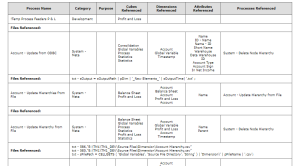
One example of what can be done with these “organic” DIY approach is to quickly create a formatted document that shows the cubes, dimensions, attributes, files, and other processes that are referenced in each of the models’ processes:
Conclusion
If you are a Planning Analytics Workspace user, the PAW Modeling workbench search will be a “go to” tool, if you are not, or want your search to cross all processes and/or rule files (including control objects) or want to save your search results (for inclusion in other documents), you may want to experiment with my “DIY” approach which:
- Is noninvasive – no special installs or setups, no additional executable
- Does not require any changes to the model
- Requires zero down time, can be used immediately
- Can be secured using standard TM1/PA security
- Provides simple, useable output in a common format (HTML)
- Can be self-updating – always up to date; run as part of a chore
- Allows for augmenting documentation with custom notations
- Documents both public and private objects and flows