
If you are more of a code-junkie at heart like me, or perhaps have come from a relational database background, you may want to think about the following concept.
By now, you most likely understand how to build cubes using Planning Analytics Workspace (PAW). If not, you can have a look here.
Similar to TM1 Architect, you can use Planning Analytics Workspace to right-click on Cubes in the Data Tree and select Create Cube, etc. PAW even provides a feature that lets you load data into a cube using drag and drop.
You see this approach used within other tools such as MS SQL Server where you can use a GUI (like Microsoft SQL Server Management Studio) to create tables within a relational database. But, although a GUI can be used, often actual SQL statements are written and used instead of the GUI.
Here is a little explanation of what I mean:
Specifically, the CREATE TABLE statement is used to create a new table in a database.
The syntax is CREATE TABLE table_name which is then followed by parameters that list the columns in the order they should appear within the new table (note: other details are also provided, such as column datatype, integrity rules, etc.). Additionally, the IF EXISTS and DROP TABLE SQL statements would be used to enable the deletion of the table from the database should the table already exist.
These statements would then be saved as part of the data definition language or DDL. Many people find it useful to generate and save the DDL for their database objects, as it gives them the ability to recreate their objects on that or another database.
Why is this interesting?
Because, in the planning analytics environment, you can similarity use the aforementioned GUI (PAW) to create your cubes, but, also like SQL Server, you can optionally use a “DDL approach” that is really just as straightforward and easy to understand. Let’s have a look.
Within PAW, right click on Processes in the Data Tree and then select Create Process.
On the Create process dialog, enter a name for the DDL process and then click on Create:
On the process Data Source screen, you can leave “No data source” selected:

Next, click on the Script tab.
You should notice that only the Prolog and Epilog sections of the process are visible.
This is because we selected no data source and only these two process sections will be executed when we run the process.
The Prolog Section
Remember, each of the sections or tabs in a TI process can be referred to as a script and have a unique purpose. The Prolog section in a TurboIntegrator process holds the actions to be executed before the designated data source is processed. Since we selected no data source, the Prolog section will run to completion and then control will go immediately to the Epilog section.
Here, in the Prolog section is where we will place our planning analytics “DDL”.
Once Again, just like with SQL, we can use the PA TurboIntegrator functions: CubeExists CubeDestroy and CubeCreate to check to see if our cube exists, drop (destroy) it if it does and then create it.
For example, if we want to create a cube named “Sample Cube” that is made up of just 3 dimensions (Dim1, Dim2 and Dim3) we can enter the following lines of script in our process:
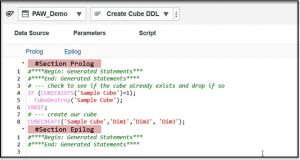
After entering the above, you can save and run the process and your cube will be created. Keep in mind this code assumes that the dimensions already exist under Dimensions in the Data Tree (if you rerun the process you will not receive any errors, since the code will destroy the cube and then recreate it).
Why take this approach?
So why take this approach? Well, you certainly can simply use the GUI to create cubes.
However, consider this:
- Dimensional Reordering! If you are prototyping a cube design and perhaps changing the order of dimensions more than a few times, dealing with the GUI may be a bit cumbersome, while updating a single line of code in the script and rerunning it is easy.
- Performance! Destroying and re-creating a cube will sacrifice the data loaded into it but this can actually be a strategy you can use to validate the expected memory consumption of a cube. That is, if you have a reasonable amount of data available, you can use the “DDL process” to quickly and efficiently change the order of the dimensions, load the data into the cube and record its “footprint”. Then, you can change the script (the dimensional order) and run it, reload the data and re-check the footprint. This will provide statistics into how the order of dimensions may impact memory consumption (and performance) once the cube is moved into production and data starts to accumulate there.
- Documentation! If you find yourself spending time building and rebuilding cubes (even going back to a previous version) during agile prototyping because of requirement changes or other discovery, the DDL process approach actually is a quick and easy way to document that effort:

- Object Migration! Finally, just like with SQL Server, this DDL process approach can be used to have the ability to recreate their objects on that or another PA environment.
Conclusion
So perhaps I am a “purest” at heart and might use “DDL Like” TurboIntegrator scripting to create cubes and dimensions during design more often than most, but I think at least considering this concept is worth a little of your time. Enjoy!