
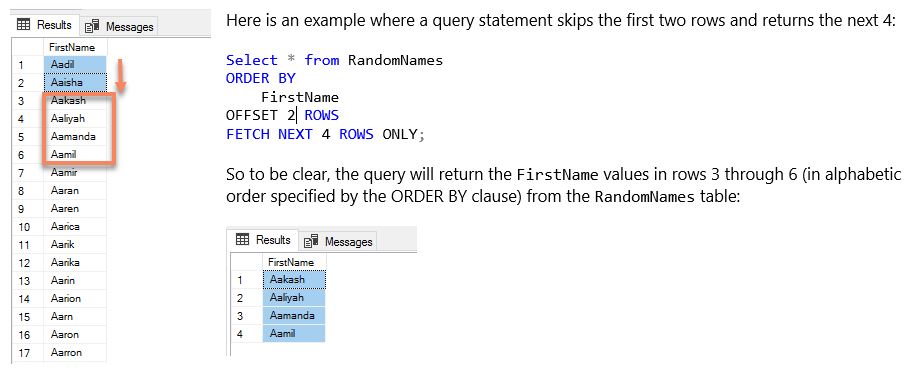
The OFFSET-FETCH filter is a SQL combination designed so that you can specify how many rows you want to skip before specifying how many rows you want to return in a SQL query.
This can come in handy in a variety of ways such as returning results to the user one “slice” at a time when the full result set is too big to fit in one screen or web page.
To use the OFFSET-FETCH filter, it requires an ORDER BY clause in a query and then must be specified right after it. You start by indicating how many rows to skip in the OFFSET clause, followed by how many rows to return in the FETCH clause.
A Planning Analytics Use Case
In Planning Analytics (PA), you use TurboIntegrator processes to query relational database tables and create and/or update cubes and dimensions from the data returned in those queries. The data is typically extracted, transformed in some way, and then loaded into dimensions and cubes for consumption by Planning Analytics users. In most cases, the relational source systems will remain what is referred to as the “system of record” and the data in Planning Analytics will be used for modeling and reporting.
In common modeling scenarios, you may encounter data that might be infrequently referenced but is useful in decision making or drawing insights from a model. For this data, it may not make sense to incur the expense of actually “loading and keeping” it within Planning Analytics but forcing an analyst to “go outside” (of Planning Analytics) to view this information is not necessarily a reasonable option.
As an alternative, you can offer Planning Analytics users the ability to dynamically query database data and then immediately “page back and forth” through the result set while remaining in Planning Analytics using a king of “VCR” control.
To keep this example simple, I am going to use the previously shown RandomNames SQL Server table which has thousands of first names extracted from a global organizations employee database. I want my users to be able to page or “scroll” forward and back through the entire list of the names in alphabetical order, 25 names at a time.
To accomplish this, first you can build a ‘relational cube” – meaning a cube with only 2 dimensions corresponding to the rows and columns that are retrieved by a SQL query. In this example I built the FETCH cube shown below:

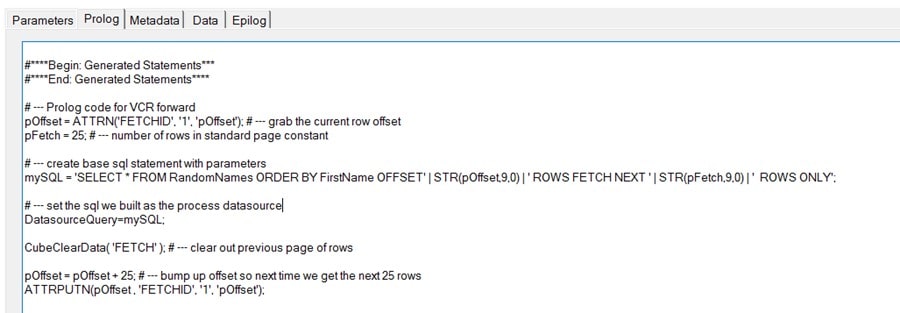
Next, we’ll create 2 TurboIntegrator processes (one to move forward and one to move back) that will query our RandomNames table through an ODBC data source. The first process will be our “go forward” process and is shown below.
Basically, this process utilizes a numeric attribute to track “what page” is currently being viewed so that it can calculate the OFFSET and FETCH parameters for the SQL query (Note that I have decided to keep the page size (FETCH value) consistent at 25).
The process then clears the previous page of data from our FETCH cube and then resets the attribute to the new OFFSET value.
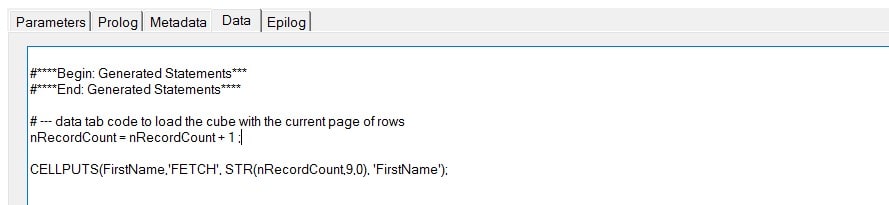
The Data tab of the process uses the value of the nRecordCount variable to insert the new records into our FETCH table:
The process to “move back” is a copy of the above process with the following exceptions: decrement the offset (rather than increment it) and then check to make sure the user hasn’t “paged beyond” the start or top of the list:

If you use your imagination, I see a more parameterized query here where you might add the ability to narrow the search for names “starting with” or “containing” or specific character or string. With an even more thought, another use case might add more columns of data might being returned, as users might want to search for sales by a customer or product or another qualifying attribute. The number of records to FETCH in a page could even be configurable.
Using Planning Analytics Workspace
With Planning Analytics Workspace (or “PAW”) it is easy work to create a new page with two buttons and a view.
The view will be a simple view of the FETCH table we created earlier.
You can use descriptive Button Text or simple characters on the buttons. For the Button Target properties, make sure you select the proper Planning Analytics Database name and Process names and also be sure to check the box labeled “Refresh after execution”. Doing this will execute the forward or back process (when you click the corresponding button) and then refresh the PAW page (and the view) after it completes.
If you the click the buttons, the view will show the next or previous 25 names from the database table.
If you make sure your database table is properly indexed, the performance will be more than reasonable and allow your Planning Analytics users to quickly access and scroll though data that is resident outside of any Planning Analytics cube and is always current since it is coming from the system of record.
Final Thoughts
The above is a simple yet working example of a single-user scenario. To support multiple users, you would have to further parameterize the FETCH table, which shouldn’t be too difficult.
You could use this concept to archive data from Planning Analytics model to a relational data mart or warehouse. For example, imagine if you kept a limited number of scenarios in Planning Analytics and at certain times this data was moved to a data warehouse. If the occasion arose where you wanted to compare information from a current scenario, perhaps a particular product, customer, or period, you could query that data directly from the warehouse table, scroll through it in Planning Analytics and even use Planning Analytics Workspace to visualize it – without having to reload it into a model.
Finally, when designing a Planning Analytics model, excluding infrequently used data (while still having access to it) will allow for a cleaner design and will typically improve the overall performance of the model, if only by reducing the total amount of data being stored and manipulated by the model.