
One of IBM Planning Analytics (PA) biggest advantages over other applications is the ability to use feeders. When it comes to issues of sparsity within cubes, feeders improve performance by giving developers a way to prevent Planning Analytics from trying to look through millions of intersections to find all the data to consolidate. Essentially, feeders are “flags” that tell Planning Analytics where to look for calculated values to consolidate. Conditional feeders use logical conditions on the right-hand side of the feeders to limit the number intersections the application needs to look for and filter through. A conditional feeder is often used in combination with a conditional statement in a corresponding rule.
Examples
To demonstrate the differences between standard and conditional feeders, I have built a set of examples using two cubes each with only two dimensions:
- Periods (time dimension)
- Feeder dimension (stand-in for a business dimension like account or cost center)
Example of a Standard Feeder
Below, I have written a simple rule without a feeder but with “SKIPCHECK” enabled at the top of my rule file. I then entered a “1” at the intersection of “201801” and “Standard Feeder”. You can see in the screen shot below that the values in the calculated cells (grey cells) are not fed because when I zero suppress my view, the calculated cells disappear.
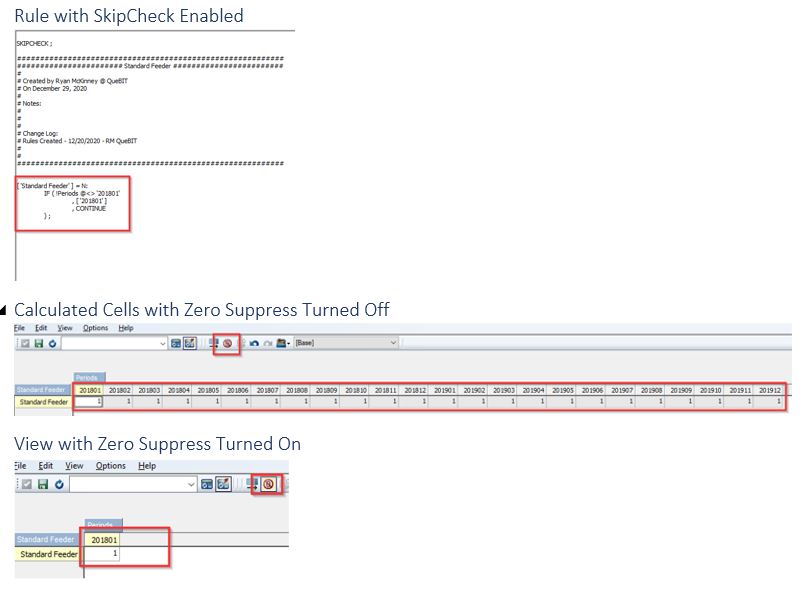
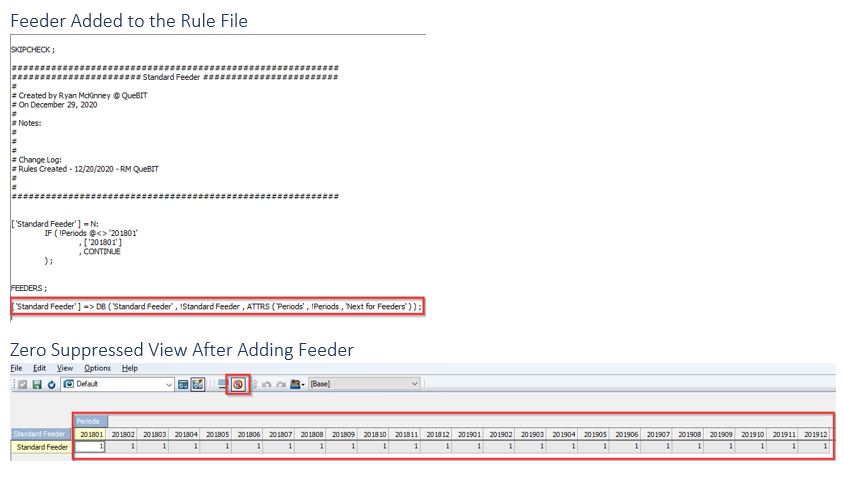
Then I add my feeder below the “FEEDERS;” statement in the rule file and my rule is now fed.
Add Condition to the Rule
It is often true that I do want or need a calculation to work across all the future periods in our time dimension. Continuing with our prior example, I add a condition to our rule to limit the calculation to the months of 2018.
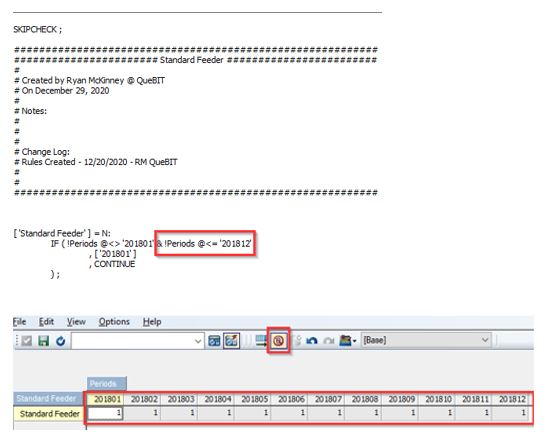
Since I did not change my feeder, I am still feeding all the months even though there is no rule calculating data in those months. This means I am overfeeding which creates inefficiencies in the model.
Example of a Conditional Feeder
To eliminate the inefficiencies created by overfeeding, I will add a condition to the feeder that aligns with the condition in the corresponding rule.
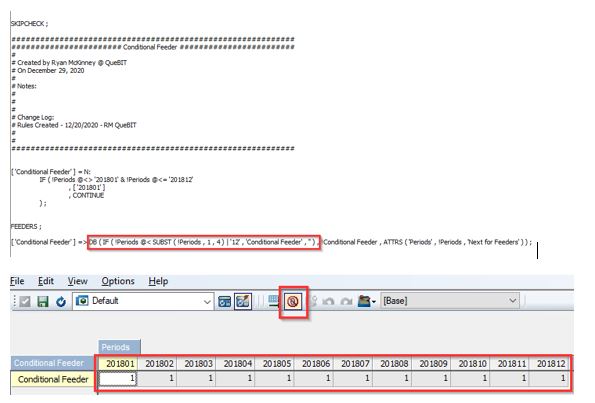
Proof the Conditional Feeders Work
Now to prove out the efficiency gains from using a conditional feeder, first I enable Performance Monitor by right clicking the name of the server and selecting “Start Performance Monitor”.
I also need to make certain Display Control Objects is enabled.
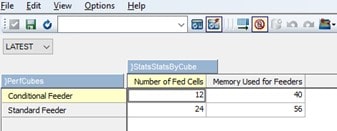
Next, I open the “}StatsByCube” control object. This contains data about cube rules and feeders. The data is the cube is updated regularly so if you do not see data in the cube right away, give it a minute or two and it will populate.

Below is the stats data about our two cubes. Notice the number of fed cells in the Conditional Feeder cube is exactly half the number seen in the Standard Feeder cube which relates directly to not feeding the 12 months of 2019 (24 – 12). The difference in the number of fed cells is giving us a 16kb savings on memory (56kb – 40kb). Though 16kb is not much, when the savings are applied across millions of intersections and across multiple cubes, it adds up quickly.
Administration of a Model with Conditional Feeders
Conditional Feeders do come with a cost and they are not needed or a good fit for all models. Below is a list of topics to consider before using conditional feeders:
- It is important to remember that for numeric cells, feeders only fire once.
- Rule of Thumb: Once fed, always fed.
- This is true until the PA instance is either restarted OR
- The data is cleared from memory
- This fact is especially important to remember when writing or changing any feeders including conditional feeders.
- Rule of Thumb: Once fed, always fed.
- Conditional feeders become invalid and must be reprocessed if the underlying condition changes
- Use the Process Feeders function in a TI when the underlying condition changes
- Intra-day feeder processing does cause locking for users which is important to keep in mind with large models where processing feeders or restarts take significant amount of time
- Use the Process Feeders function in a TI when the underlying condition changes
OR
- Restart the PA instance